How we measured time to first token
The bar chart on the main page uses a deliberately simple, informal check. It is a heuristic, not a formal benchmark, and the numbers are only meant to show rough ordering between products under similar conditions.
What we did
We used the browser’s own performance / developer tooling to time how long it takes for the first model token to appear after sending a new message. This is a basic monitor of perceived latency in the UI: no controlled lab, no server-side instrumentation, and no claim of statistical rigor. Results will vary with network, region, and load.
Prompt (anti-cache)
To reduce the effect of provider prompt caching, each send used the same one-off test phrase, including a random suffix:
What does the fox say? skmsdi31
Models
We compared products using the same fast, non–reasoning “instant” class of model where available. On AgentChat and T3Chat that was Kimi K2 Instant. For ChatGPT and Google Gemini we used the closest equivalent: non-thinking, fast chat modes (e.g. ChatGPT Instant, Gemini fast / non-reasoning), not their heavy reasoning or long-context products.
Reported medians (April 2026)
Approximate time from send to first visible token, same test prompt and class of model as above.
Screenshots
Below are a couple of raw captures from the same style of measurement. They illustrate the setup; they are not a complete data set.
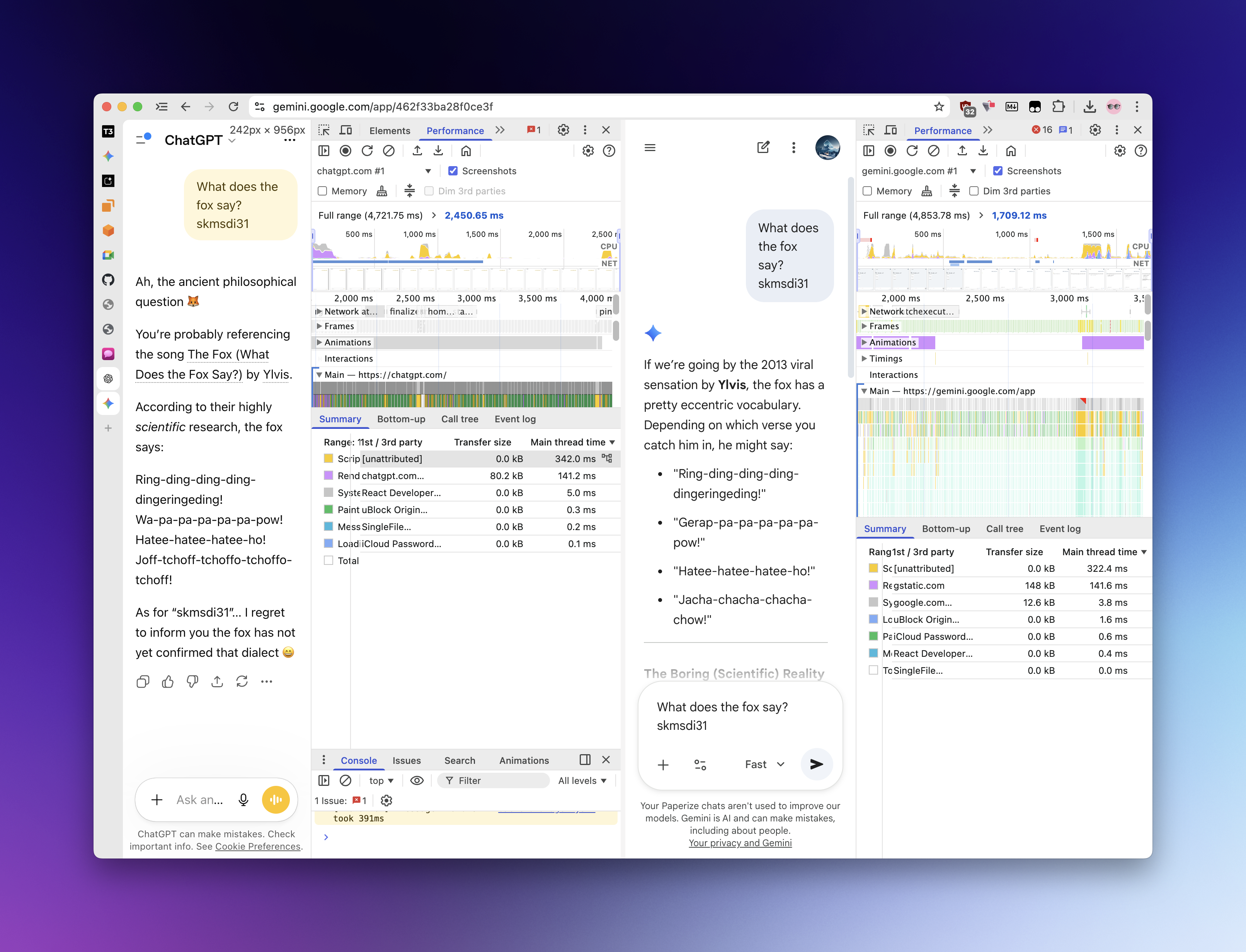
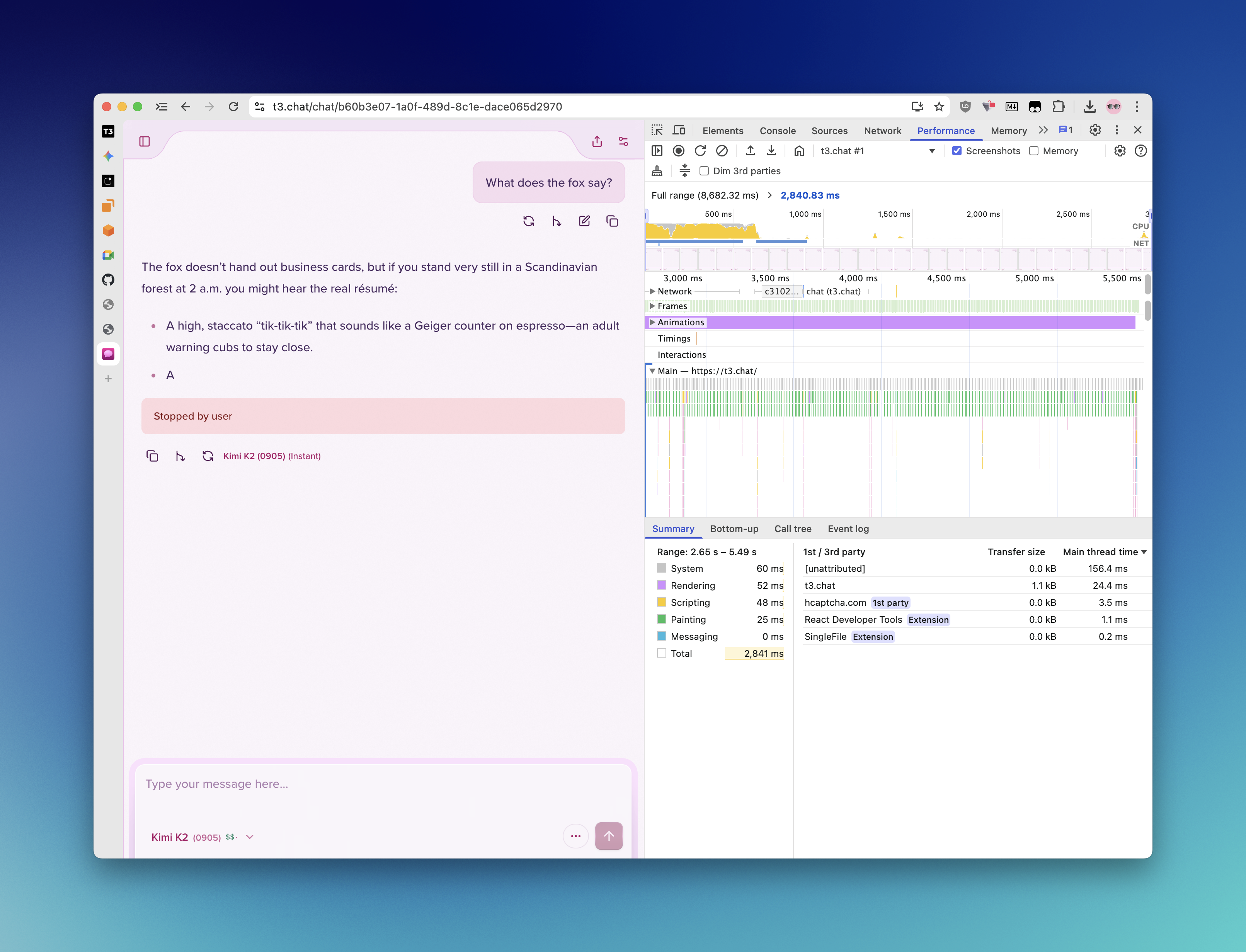
If you are evaluating providers for production, you should run your own tests in your own regions and with your own prompts. This page exists so we are transparent that our marketing number is a rough, in-browser spot check, not a whitepaper.